





头条为何能取得成功?很多人会说是头条的个性化推荐技术做得好,个人认为其实不尽然。本文罗列了相关的个性化推荐技术,特别是资讯推荐常用的算法,带大家从“内行”的角度来解密下个性化资讯推荐技术。希望读者读后能发自内心地觉得:头条其实也就那么回事。
本文主体分以下三个大的部分。除此以外也会在最后用一小节展望下个性化资讯推荐的未来。
1.个性化资讯产品:先介绍资讯推荐产品是什么,着重分析其业务特点。
2.个性化推荐方案:接着介绍资讯推荐所需的技术,着重分析其技术难点。
3.个性化推荐算法:最后介绍业界常用的个性化推荐算法。
4.个性化资讯产品
资讯推荐产品要解决用户需求很简单,一句就可以概括:为用户找到有趣的资讯。而做到这个需求就要做好两个关键点:
1.新闻聚合。用户希望在一个产品里获取任何他想要或者可能想要的东西,这就要求产品要聚合其他app、网站、甚至线下媒体里的各种资讯,这也是最基本的一个产品特性。
2.个性化。要去最大程度地理解、猜测用户的兴趣,结合兴趣为其推荐相关资讯,这是资讯产品后期衍生出来的一个产品特性。
更进一步,如果将上述两个关键点展开,一个好的个性化资讯产品就要具备以下亮点:
1. 时效性
这是所有资讯类产品共同的特性,而不仅仅是资讯推荐类产品。人们总是希望通过你的产品看到最近发生了什么,而不是很久之前的老新闻。
2. 精准性
每天发生的事情有很多,对应的新闻稿子也非常多,如果每个都看,信息过载的问题会让人吃不消。你能否猜出我的兴趣,并精准地推荐感兴趣的新闻才是用户关心的,也是用户能直接感受到的体验。
3. 丰富性
这点恰是很多用户最容易忽略的一个点。其实很多用户才不管这个资讯类产品是怎么推出来的,对于单个用户而言,其第一诉求必然是通过这个产品来了解世界,知道每天都在发生什么,所以新闻的丰富性是最最基本的。
4. 排他性
每天描述同一事件稿子很多,在自媒体时代这个问题更加突出,但用户只会用有限时间去了解这件事,而不是去研究所有关于这件事的报道,更不想甄别不同报道的差异。所以,用户往往需要的是一个事情的一两个报道,保证给我差异化的内容是必须的。
5. 热门性
谁都不想在周围朋友们讨论热点事件时,自己是个懵逼,什么都不知道。这点很关键,跟精准性和个性化看起来有点背道而驰,但人性天生就有求同的天性。没有同样的话题,生活将会失去太多色彩,不知道该和人交流什么。
6. 高质量
媒体质量层次不齐,有的文章写得很好很炫,读的时候很过瘾,但一旦你发现它是一个假新闻或者歪曲报道,你还是对这类文章嗤之以鼻。新闻可以高于事实,但不能背离事实。
7. 合法性
人总是对非法的事情感兴趣,如黄赌毒之类。而对于被压抑的需求,则更是感兴趣,如色情之类。但一个伟大的产品,首先必须是一个合法的产品。所以,一切尽在不言中了。
个性化推荐方案
要做到上一节提到的产品特性,有两条路可以走:人工运营和算法推荐。在类头条产品出现之前,请新闻方面专业人才来运营是最稳妥的方式。但人工运营成本越来越高,局限性越来越明显。走算法推荐的路,在张扬个性的年代,是一条必由之路。下表简要对比下两者的差别。

推荐算法应用在资讯类产品时有一些挑战,这也是资讯推荐能否做好的关键所在。
● 可扩展性
推荐本质是建立user和item的关联,一般问题要么是user侧量级大,要么是item侧量级大,而资讯推荐是典型的“双大”场景。又由于是高度依赖个性化的场景,还不能简单地将某一侧大幅降维,所以可扩展性显得尤为重要。
● 稀疏性
资讯的高度个性化自然而然的带来一个很棘手的问题就是稀疏性。举个最简单的例子,如果将user和item的 点击行为用矩阵形式表示出来,会发现比一般问题更多的0项存在。而稀疏问题是一直困扰机器学习高效建模的一大难题。

● 冷启动
每天都有大量的新闻产生,如何将如此多的新闻快速、合理地冷启动,尽快将高质量的新闻推给合适的用户是个大问题。
● 时效性
不同于商品、书籍、电影、视频等的推荐,新闻一大特点是生命周期非常短,有的甚至只有几个小时。如何在最短的时间里把新闻推给感兴趣的人,在新闻进入“暮年”之前发挥它的最大价值是个非常重要的问题。
● 质量保证
新闻本身量大,且时效性强,如何在短时间里快速评估每篇稿子的质量和合法性,做到最高效、最精准的内容审核是个大课题。
● 动态性
这里的动态性主要体现为用户兴趣随时间改变、当前热点随时间改变。用户在一天里的不同时刻、不同地点、不同上下文里的阅读兴趣都有所差别,动态在变化。
个性化推荐算法
围绕上面这几个挑战,业界各大资讯类产品在做推荐时想出了各种招儿来解决,接下来,我们就梳理下业界经典的做法。这里以产品为主线,以具体要解决的问题为辅线来进行梳理,会集中介绍下Google News、Yahoo Today、今日头条等产品的推荐算法,并着重介绍下深度学习在这个领域的最新进展。
● Google News
Google News是一款经典的资讯推荐产品,也是后来者竞相模仿的对象。2007年,Google News在www上首次发表论文《Google News Personalization: Scalable Online Collaborative Filtering》公开资讯推荐技术。该论文的做法非常自然、简洁,从论文题目就能看出是CF的落地上线。Google是这样想的:鉴于大家都觉得CF是推荐领域公认的有效算法,那将其直接用在产品上效果自然也不会太差。
但经典的CF有个巨大的问题,无论是user-based还是item-based,当你要算任意两个user或者两个item之间相似度的时候,计算量会非常巨大。因为CF的计算量直接取决于特征维数和user、item pairs的数目,而资讯类产品这两个数目都非常巨大:
每个user、item的特征因为大多是曝光、点击等行为类特征,而资讯类产品这些行为发生的cost很小几乎可以忽略不计,导致维度往往比较高;
资讯类产品的user数目和item数目都很大,这和一般领域往往只有一方比较大是不同的。
Google这篇论文的核心就是将CF改造为支持大规模计算的方法。
其原理也很简单:将用户事先分成群,再做user-based CF时实际变成了(user) cluster-based CF。这样在工程实现上就简化了很多,线上只需要记录每群用户喜欢什么(实际做法是用到了基于的内存key-value系统,key为资讯ID,而value则是资讯在用户群上的各种统计值)。一个用户来了之后,先找到其对应的群,再推荐这个群喜欢的资讯就好。而线下则借助Map-Reduce实现了MinHash、PLSI两种聚类分群算法,定时把最新分群结果推到线上。
为什么Google News会先选择协同过滤算法呢?除了CF算法在其他场景有成功的应用之外,还有一个重要的特点:CF是一个依赖用户行为数据就可以work的算法,它不像其他基于内容推荐的算法对NLP能力要求很高。选择CF,则绕过了NLP这个拦路虎(有经验的人都知道,NLP是一个长期积累的过程,很难一开始就做到比较出色的程度)。透过这篇文章,我们也不难发现工业界解决实际问题时的一个基本套路:重头做一个模型时,会选择最经典的一个实现,然后快速上线解决一大半问题。
结合前面总结的资讯推荐的挑战,可以看到该算法主要解决了可扩展性问题。我们也不难发现这个user cluster-based的算法也有一些明显的缺点:1)它不能解决新用户、新资讯的冷启动,因为没有行为数据来支撑CF运转;2)推荐精度不够高,没有做到真正的个性化。这是cluster-based CF算法本身的特点决定的;3)实时性不够。用户聚类不能做到快速更新,这导致了对用户最新兴趣把握有不及时的风险。这些问题在Google News的另一篇论文中得到了解决。
Google News在www 2010上放出了《Personalized News Recommendation Based on Click Behavior》。这篇文章重点解决推荐精准性和新资讯的冷启动问题,文章想法也很朴素自然,主要是基于贝叶斯理论进行建模。他们假设用户兴趣有两个方面:个人不断变化的兴趣以及当前新闻热点。在具体建模之前,作者先基于历史数据进行了统计分析,验证了他们的假设,得到如下基本结论:用户的兴趣是随时间变化的,新闻热点也是随时间变化的。还有一个比较比较有趣的结论是不同地区同一时间的新闻热点是不一样的。下图是不同地区不同时刻体育类新闻的阅读占比。
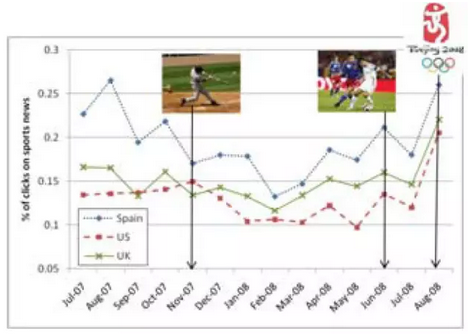
这幅图纵轴是体育新闻阅读量在该地区总新闻阅读量的占比,越高表示该地区的用户越喜欢看体育新闻。横轴则是时间点,用黑线标示出的三个时间点从右到左则分别对应奥运会、欧洲杯以及美国职业棒球大联盟进行时。而图中的三条不同(颜色)标示的线则代表西班牙、美国、英国三个地区。不难发现,这副图不仅揭示了同一地区用户对体育新闻的感兴趣程度是随时间变化的,更揭示出西班牙、英国等国家更爱看体育新闻。
方法主要建模用户对当前某类新闻的感兴趣的程度,这取决于两个方面:用户对这类新闻的兴趣度以及当前某类新闻的热度。通过贝叶斯理论,这两个方面可以直接用如下公式联系在一起:

其中分子左半部分
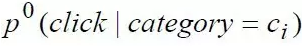
表示用户当前对某类新闻感兴趣的概率,它是通过最近不同时间段用户对某类新闻感兴趣的程度来汇总计算,而用户某个时间段内对一类新闻感兴趣的程度则通过下式计算。
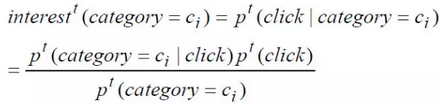
这个公式粗看起来比较复杂,实际含义其实很简单,可以理解为简单统计下某类新闻阅读量占用户该时间段内所有新闻阅读量的比例即可。而分子右半部分
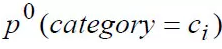
表示当前本地区某类新闻的热度(这类新闻被该地区点击的概率),实际也是统计一下短时间内对这类新闻的用户点击占比得到的。
总体来看,该算法是非常简洁自然的,它针对CF遗留的问题进行了很好的解决:1)引入新闻类别解决了新新闻的冷启动;2)引入用户兴趣解决了个性化和推荐精确度的问题。但新用户冷启动还有优化的空间,因为按照这个方法,同一地区不同新用户推荐的都是该地区最热门的内容。
● Yahoo Today
Yahoo Today团队2009年在WWW上发表 《Personalized Recommendation on Dynamic Content Using Predictive Bilinear Models》,重点解决资讯推荐里的冷启动问题。不同于上一篇google news的做法,这篇文章试图同时解决新用户和新资讯的冷启动。本文的基本假设:用户画像能刻画用户的阅读兴趣,新闻的画像也可以表示新闻的点击率,而用户喜欢一条新闻的程度则取决于静态预测和动态预测两个方面,都是用feature-based learning方法来建模用户对资讯感兴趣的程度。具体来讲,用户xi对资讯zj的兴趣得分如下计算。
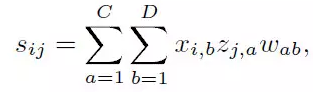
所谓的 bilinear model 的含义当你隐去一个自变量时,另一个自变量和因变量成线性关系。比如下式不考虑z时,s和x成线性关系;不考虑x时,s和z也成线性关系。进一步如果将用户和资讯的特征分为静态和动态两大类,则上式可写为:
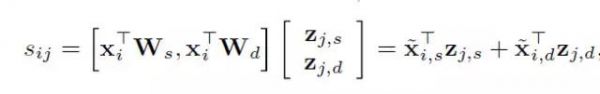
最后一个等式后面的第一项是静态预测得分,第二项则是动态预测的得分。
所以当一个新的用户到来时,第二项的特征是没有,相当于仅用用户的画像等静态特征来解决新用户的预测问题。当一个新资讯时,也是同样的道理。静态特征如搜集到的用户的年龄、性别、地域等基础属性,以及从其他途径获取的如在相似产品上的行为、其他场景上的历史信息等,还有资讯的类目、主题等。而动态特征如用户在Yahoo Today上的各种阅读、点击、评分以及加工出来的某条资讯、某类资讯分时间段的各种统计值等。有了预测分s,和真实的label (比如用户是否点击一个资讯r(i,j))做个比较就能得到机器学习训练时的反馈信息。本文优化目标是基于贝叶斯理论推导出来的最大化后验概率(maximum-a-posteriori, MAP),而优化方法则采用熟知的梯度下降法(gradient-descent, GD)。
2010年,Yahoo又发表了一篇更加有效解决冷启动的文章《A Contextual-Bandit Approach to Personalized News Article Recommendation》。这篇文章基于传统的Explore-Exploit(EE)套路,大家可能比较熟悉的是为新item随机一部分流量让其曝光,得到一些反馈,然后模型才能对其有较好的建模能力,这是最na?ve的EE策略。
稍微高大上一点的做法则是upper confidence bound(UCB)策略: 假设有K个新item没有任何先验,每个item的回报也完全不知道。每个item的回报均值都有个置信区间,而随着试验次数增加,置信区间会变窄,对应的是最大置信边界向均值靠拢。如果每次投放时,我们选择置信区间上限最大的那个,则就是UCB策略。这个策略的原理也很好理解,说白了就是实现了两种期望的效果:
1.均值差不多时,每次优先给统计不那么充分的资讯多些曝光;
2.均值有差异时,优先出效果好的。
而yahoo这篇文章,则是对UCB进行了优化,因为UCB对item没有任何先验知识,而linUCB可以引入一些先验知识。比如你在推荐新闻时,可能发现娱乐类新闻天然比体育类新闻点击率高。如果能把这个信息作为先验知识考虑进EE策略中,就可以加速EE的效率。LinUCB假设每次曝光的回报是和Feature(user, item) 成linear关系的,然后使用model预估期望点击和置信区间来加速收敛。
深度学习篇
日益红火的深度学习也在不断影响着资讯推荐,在这一节就简要review下最近爆出来的几篇相关文章,大致可以分为两类:
1)embedding技术。此时深度学习主要用来学习user/item的embedding也就是通常意义上的user/item的表示形式,每个user/item可以表示为一个向量,向量之间的相似度可以用来改善推荐。这里深度学习的重点是用来学习合理的表示;
2)使用深度学习直接对预测目标建模。此时深度学习的重点放在最终要解决的问题上。初看起来似乎第一种形式不如后者来得直接,但第一种形式在实际应用中通常能起到简化架构、快速解决问题的功效,还能作为一个基础特征来改进线上其他环节的效果。下面我们分别选择一两篇有代表性的文章来进行科普。
Yahoo Japan的新闻推荐团队利用denoising autoencode的技术来学习新闻的vector表示。Autoencode大家可能比较熟悉,它通过最小化变换前后信号的误差来求解,而denoising则是对输入随机加入一些噪声,再对其进行变换输出,最终是通过最小化加噪声后的输出和原始(不加噪声)输入之间的差异来求解。应用中不少结果表明,这种方法比传统的autoencode学习到的vector效果更好。具体示意图如下。
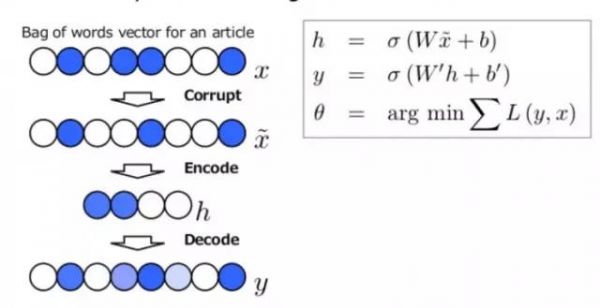
但这种方法是经典的无监督学习套路,直观来看和应用场景中要求相似新闻的vector也要尽量相似没有直接的关联(这里单单从优化目标来看,实际上由于语料的天然性质或者人们用语习惯,这个相似性的要求已经间接隐含在优化目标里了)。而新闻有很多人们编辑好或者其他模型产生好的类别信息,假如A、B新闻都是体育类,C是教育类的,通常意义上来讲A和B相似度是比A和C要高的。这是在训练深度学习时已知的先验知识,如果能把它加入到优化目标中,学习到的vector就能更好的表达相似度信息,于是有了下面的方法。

如图所示,通过在原始autoencode的优化目标中加入“同类新闻相似度大于不同类新闻相似度”这一项,我们就可以把先验知识作为约束加到模型中。Yahoo Japan的人实验证明了如此得到的vector确实能更好的表示(相似度信息)。
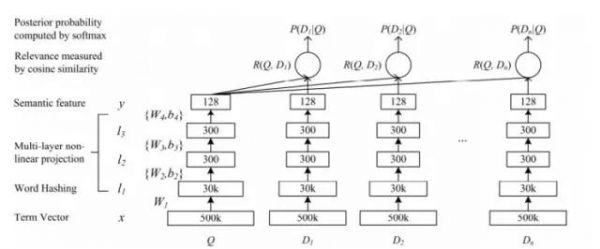
微软研究院也提出过一种很有趣的得到item表示的方法。作者利用用户的搜索日志,同一个query下,搜索引擎往往返回n篇doc,用户一般会点击相关的doc,不太相关的一般不会点,利用这个反馈信息也可以训练神经网络。具体示意图如下,这里的优化目标就是要求点击的一个doc_i的预测得分p(D_i|Q)要高于不点击的,论文基于这个信息构造除了损失函数,也就得到了最终机器学习可以优化的一个目标。
目前只介绍了如何得到item的vector,实际推荐中要用到的一般是user对一个item的兴趣程度,只有在得到user vector后才能通过算user和item的相似度来度量这个兴趣程度。那么如何得到user的vector呢?了解的同学可能能想到,既然我们已经得到了新闻的item的表示,想办法把他们传到user侧不就行了么?
确实如此,一种简单的做法是把用户近期点过的所有新闻的vector取个平均或者加权平均就可以得到user的vector了。但这种模式还有优化的空间:1)用户点击是一个序列,每次点击不是独立的,如果把序列考虑进去就有可能得到更好的表示;2)点击行为和曝光是有联系的,点击率更能体现用户对某个或某类新闻的感兴趣程度。鉴于这两点,我们很容易想到通过深度学习里经典的解决序列学习的RNN方法,Yahoo japan的人使用的就是一个经典的RNN特例:LSTM。训练时将用户的曝光和点击行为作为一个序列,每次有点或不点这样的反馈,就很容易套用LSTM训练得到user的vector,具体做法如下图所示。
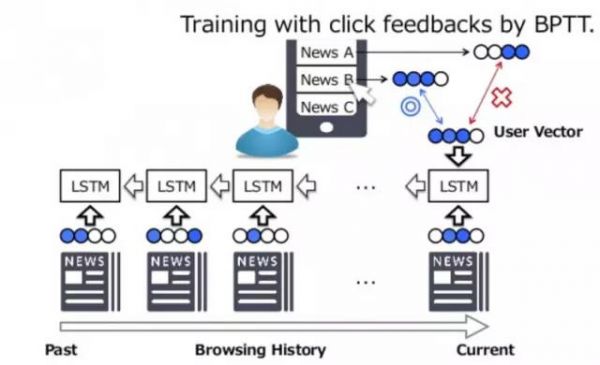
微软还发表了《A Multi-View Deep Learning Approach for Cross Domain User Modeling in Recommendation Systems》,文章提出了一种有趣的得到user vector的方法,这是一个典型的multi-view learning的方法。现在很多公司都不仅仅只有一个产品,而是有多个产品线。比如微软可能就有搜索、新闻、appstore、xbox等产品,如果将用户在这些产品上的行为(反馈)统一在一起训练一个深度学习网络,就能很好的解决单个产品上(用户)冷启动、稀疏等问题。具体网络结构如下,总体的优化目标是保证在所有视图上user和正向反馈的item的相似度大于随机选取的无反馈或者负向反馈的相似度,并且越大越好。用数学公式形式化出来是:
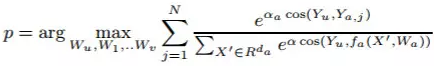
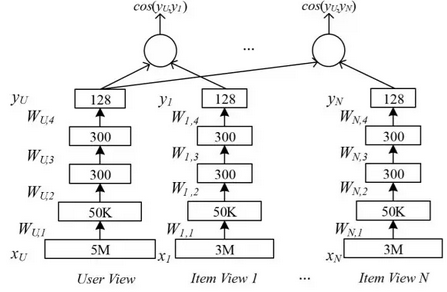
对应的神经网络结构如下图所示。
今日头条
作为国内当红的个性化推荐产品,今日头条技术经历了三个阶段:
1)早期以非个性化推荐为主,重点解决热文推荐和新文推荐,这个阶段对于用户和新闻的刻画粒度也比较粗,并没有大规模运用推荐算法。
2)中期以个性化推荐算法为主,主要基于协同过滤和内容推荐两种方式。协同过滤技术和前面介绍的大同小异,不再赘述。基于内容推荐的方式,则借助传统的NLP、word2vec和LDA对新闻有了更多的刻画,然后利用用户的正反馈(如点击,阅读时长、分享、收藏、评论等)和负反馈(如不感兴趣等)建立用户和新闻标签之间的联系,从而来进行统计建模。
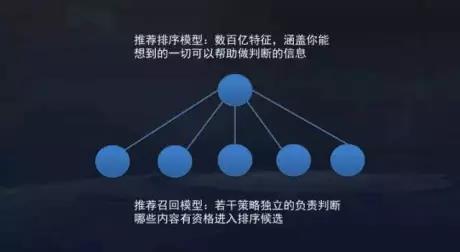
3)当前以大规模实时机器学习算法为主,用到的特征达千亿级别,能做到分钟级更新模型。 架构分为两层(图来自头条架构师的分享):
检索层,有多个检索分支,拉出用户感兴趣的新闻候选;
打分层,基于用户特征、新闻特征、环境特征三大类特征使用实时学习进行建模打分。值得一提的是,实际排序时候并不完全按照模型打分排序,会有一些特定的业务逻辑综合在一起进行最终排序并吐给用户。
任何一种算法都有其局限性,业务要结合自己产品的特点,选择合适的算法解决特定的小问题,融合各种算法解决一个大问题。另外要设计合理的实验和放量机制,以在有限的影响内,最大程度地利用真实的用户行为来修正算法判定的结果。比如,可以先放5%的流量来试探用户对新闻的兴趣,并用模型进行建模;再用15%的流量来修正模型的效果,进行优胜劣汰;最后将真正置信的推荐结果推送到全量用户。
个性化资讯推荐的未来
个资讯消费是人的基本需求,个性化资讯推荐让我们能更好地消费资讯,享受生活的快乐。个性化资讯推荐还有很长的路要走,目前面世的产品仅仅迈出了第一步,看起来有模有样,实际上问题多多。例如被吐槽最多的一个问题:用户一天看了很多,但睡前闭目一想,记住的很少,对自己有用的更是凤毛麟角。这只是一个表象,背后其实暴露了很多现有推荐的问题。
要做好一个资讯推荐产品,不单单精准推荐技术需要演进,呈现形式、交互方式、产品形态、内容生态等等都需要去探索,最最重要的要想清楚以下几个本质问题:
1.人为什么需要阅读?
2.人为什么会消费资讯?
3.用户为什么需要到你这阅读资讯?
4.好的阅读体验到底是什么,如何量化?
5.产品推荐的基因是什么?
加油吧,个性化资讯推荐!
参考文献:
1. 桑赓陶,《 把握市场、产品和技术的动态匹配——韩国三星电子公司产品开发战略演变的基本原则及其对中国企业的启示》
2. Personalized Recommendation on Dynamic Content Using Predictive Bilinear Models[www, 2009]
3. Google News Personalization: Scalable Online Collaborative Filtering [www,2007]
4. http://www.slideshare.net/techblogyahoo/deep-learning-for-news-recommendation [slideshare, 2016]
5. A Survey on Challenges and Methods in News Recommendation[WEBIST, 2014]
6. Personalized News Recommendation Based on Click Behavior[www, 2010]
7. A Contextual-Bandit Approach to Personalized News Article Recommendation[www, 2010]
8. Learning Deep Structured Semantic Models for Web Search using Clickthrough Data
9. A Multi-View Deep Learning Approach for Cross Domain User Modeling in Recommendation Systems [MS Research]
10. http://www.ruanyifeng.com/blog/2012/03/ranking_algorithm_wilson_score_interval.html
11. https://zhuanlan.zhihu.com/p/21404922
12. http://www.36dsj.com/archives/36571
另:如何看待头条的成功?
网上很多人都从各种角度有过分析,但大都是通过现象来解释现象,抓住本质的不多。个人比较喜欢用“市场、产品和技术”动态匹配理论来看这个问题[1]:对于一个特定的企业来说,它在特定时点上所找到的、要去满足的市场是特定的;特定的市场要求企业用特定的产品去满足,而特定产品则是特定技术的某种物化。企业只有掌握相应的特定技术或者有能力在一定的时间内把这种特定技术开发出来并把它物化成特定产品,企业选择的特定市场才有可能得到满足。
用动态匹配理论来看头条,可以看到它的成功是如此之合理。随着资讯市场的成熟和发展,人们需要一个在碎片时间消费有趣资讯的产品,来解决用户的需求。这里的有趣因人而异,就需要用个性化的推荐技术去满足。如此看来,头条在合适的时机,用合适的技术做了合适的产品,造就了自己的成功。















